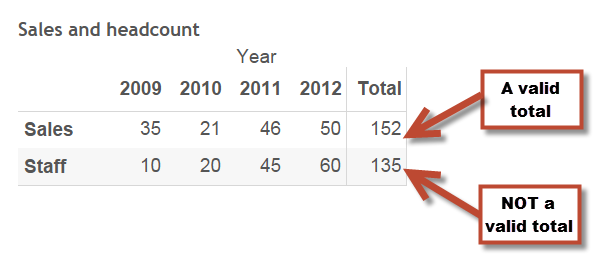
Here’s a new-to-me problem: a dataset has two measures, and they’re both different types, but is there a term for the two types?
Here’s my data: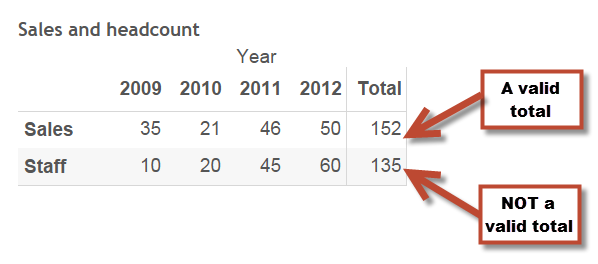
“Sales” can be shown broken down by year or as a total because a sale is only counted in one year
“Staff” cannot be totalled across all years because some of the staff are being counted in all years. I don’t have 135 staff, I have 60.
Is there a term for these two measures as they appear in a dataset? I’m thinking that “Staff” is cumulative, maybe? Sales are discrete? But that doesn’t sound right…
Help!

7 Comments
Add Yours →I would use additive and non-additive.
http://www.geekinterview.com/question_details/15242
Andy, hi! In math (maybe too technical) numbers that can be summed are called Additive and otherwise they are called Non-Additive.
Examples of non-additive numbers would unique users to a website or staff members of a company, where the total must be calculated from a count distinct over the whole set of IDs rather than summed across existing counts.
To make things more complex, there are some exceptions and these are called Semi-Additive numbers. Unique users are and staff numbers are actually semi-additive because if you take mutually exclusive groups, for example staff whose home office is London vs staff whose home office is Paris, those numbers can be summed.
Hope that’s any good!
What you’re really looking at here is that sales is a yearly value (i.e., essentially sales/year), so you can sum them across years, multiply them by number of years, etc. Staff is not per year, so that way of totaling the values doesn’t work.
I guess cumulative gets close, but it’s really a question of units.
I think of this with the terms ‘Bucket’ and ‘Snapshot’.
When dealing with data that is bucketed, a sum makes sense, while that that is a snapshot, summing does not make sense.
Sales is bucketed into each year, and can be reasonably aggregated to any granularity. A weighted average is also a bucked measure.
Staff is a snapshot count, an amount measured at a point in time. If the data displayed is the granularity of the underlying data, a sum aggregation does not make sense, an average, or as you suggested a last may make more sense.
It would be more ideal to have the raw data, and perform a Count Distinct on a Staff ID, to get an aggregation at any granularity, unfortunately raw data is not always available.
Ok, I replied to your linkedIn, and immediately after had this nagging feeling I knew the answer but wasn’t quite there! It’s ‘Additive’ and ‘Non-Additive’!
Take a look here: http://www.zentut.com/data-warehouse/fact-table/
Using database terminology, first one is an additive measure, second one is a semi-additive measure since you can still add them across different dimensions except time e.g. your staffing could be broken down across different job titles and you could still add the numbers to get complete staff count for a given year.
Your comparing two different animals; see als Joe:
Row 1 Sales is a flow : a rate of dollars per period. So this is a change between the total at two year ends, If you add another row with the cumulative balance of sales at year end you see how they relate to the total in the 5th column.
With staff I assume you state in the second row the population at the end of the period, the so called balance or population at a certain moment ( 31-12-xx). It doesnt make sense to add up 4 stocks at year end. The only number that counts is the last 60 in year 4 and you already have that. So the 5th total has no meaning as a measure of a cumulative flow during 4 years . If you calculate the nett flow of people in and out those 4 years in another row you will see what I mean. The total of that flow does have a meaning because it adds up to 60 and this is the flow of people in and out. So never compare a flow of cows and and a balance of horses!
Make 4 rows ( flows and totals at year end for both sales and people ) and total only the flows. The totals at year end take care of themselves at the end of the last period.