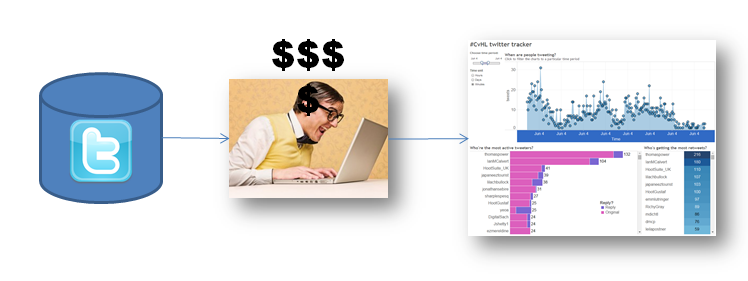
Let’s say I need some basic Twitter data. What’s the difference between these two scenarios?
Scenario 1
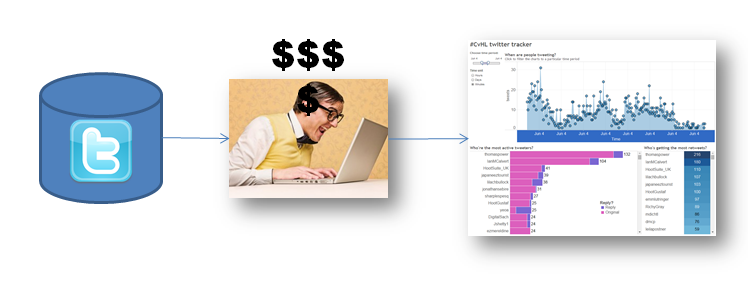
I pay a developer to write a script using Twitter’s free API and they push the data into a spreadsheet for me.
Scenario 2
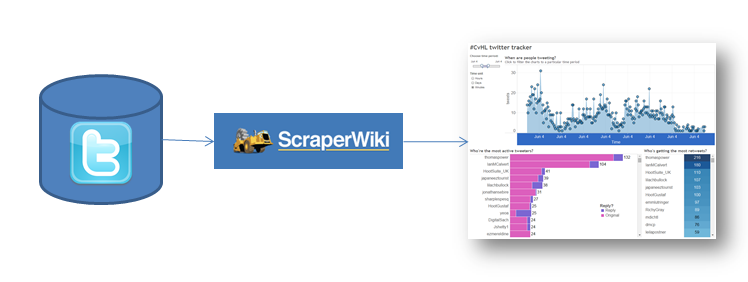
I connect to Scraperwiki, who have automated the work of the developer, and use their tools to push tweets into a spreadsheet.
Scraperwiki is a great company. They have been able to provide Twitter data for the non-programmer. I’ve used their tools to do effective analysis that highlights the power of Twitter data. I am very disappointed that Twitter has forced them to turn off their Twitter tools. I appreciate Twitter is a business and has to make money, but this decision does not aid data democracy.
The decision favours developers and hinders data enthusiasts. Why? What makes developers a better class of person in Twitter’s eyes? Why can developers with their fancy pants Python, PhP and Ruby skills get their hands on the data, but the rest of the world can’t?
Scraperwiki’s service, in my eyes, removed the middle man for those who don’t know how to code.
Apart from keeping developers in business, I don’t see the difference between the scenarios. Feel free to explain it to me in the comments.
Twitter, if you’re listening, why don’t you support data democracy?

2 Comments
Add Yours →Yeah that makes no sense to me. Don’t understand what the difference is between me using the API myself to write something or use someone elses to get the same thing.
The difference is that Twitter still, for the moment, needs to keep developers onside. Once they get a bit bigger I imagine they’ll block API access for developers as well. Or start charging for it.
Make no mistake: if you put your data into Twitter, it’s not your data any more. If you want to keep ownership of your data, use a more open service.