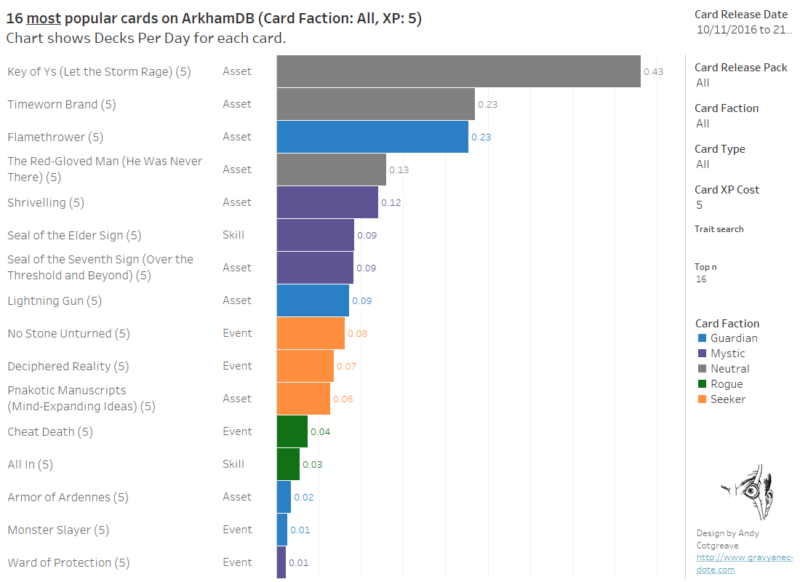
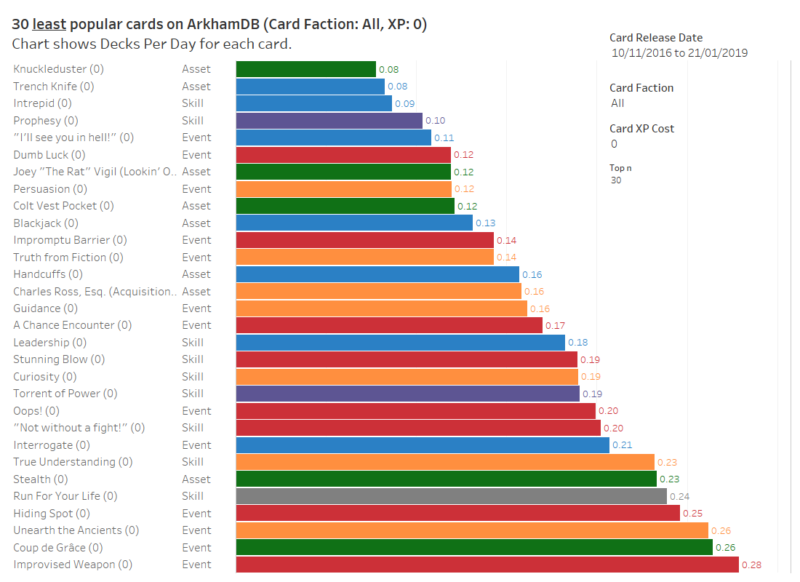
ArkhamDB: building the least popular decks (Guardian and Seeker) Post date February 28, 2019 Comments 0




Recent Comments