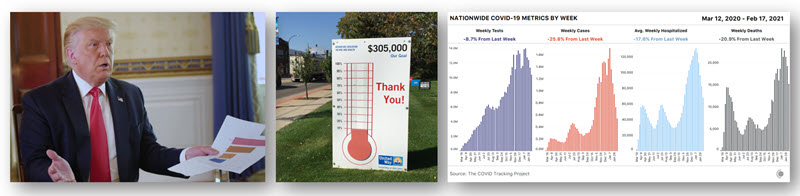
Trump’s literacy, KPIs and Citizen Data: final lessons from covid-19 charts Post date March 1, 2021 Comments 1
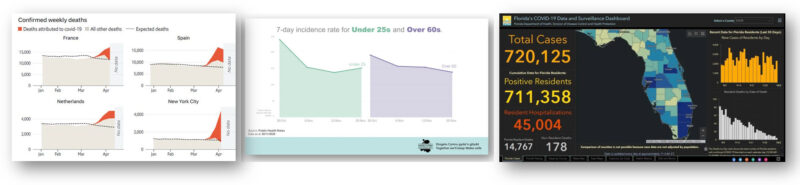
After 12 months of covid-19 charts, what have we learnt? (Sweet Spot #58) Post date January 21, 2021 Comments 3
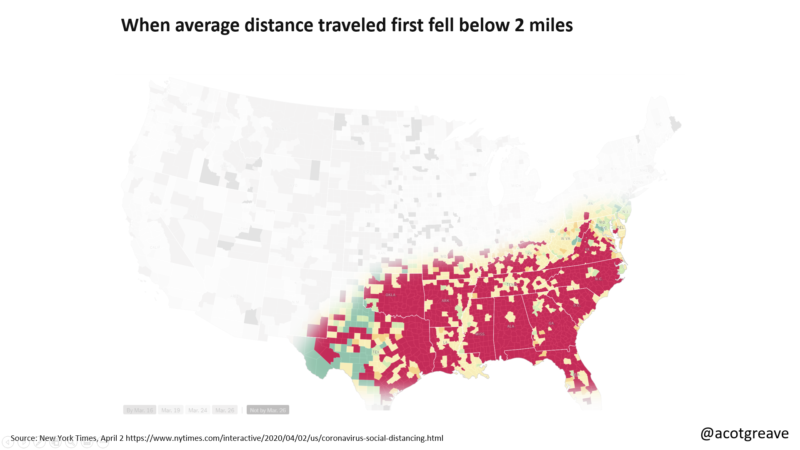
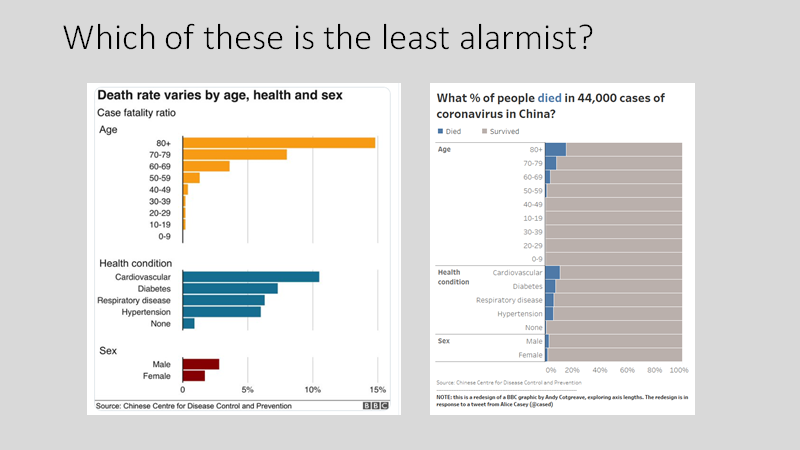
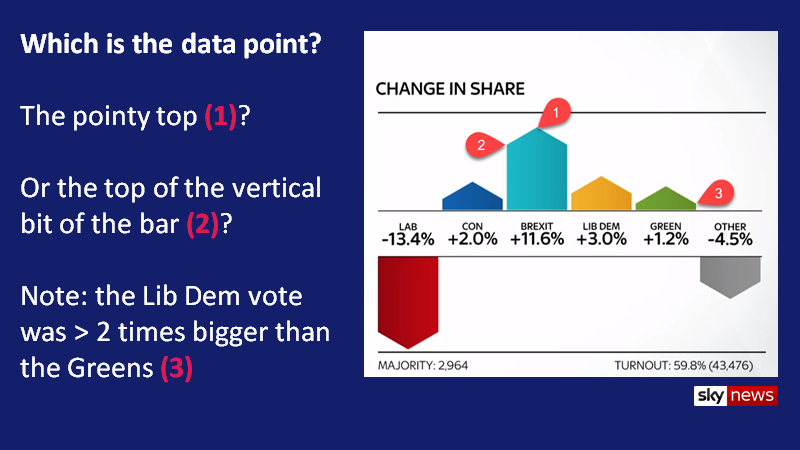
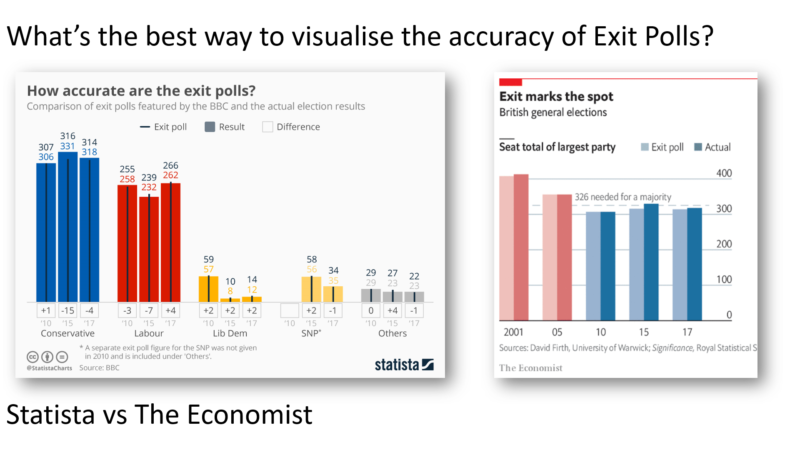
During the coronavirus outbreak, should we change the data visualization rules? Post date March 2, 2020 Comments 9



Recent Comments