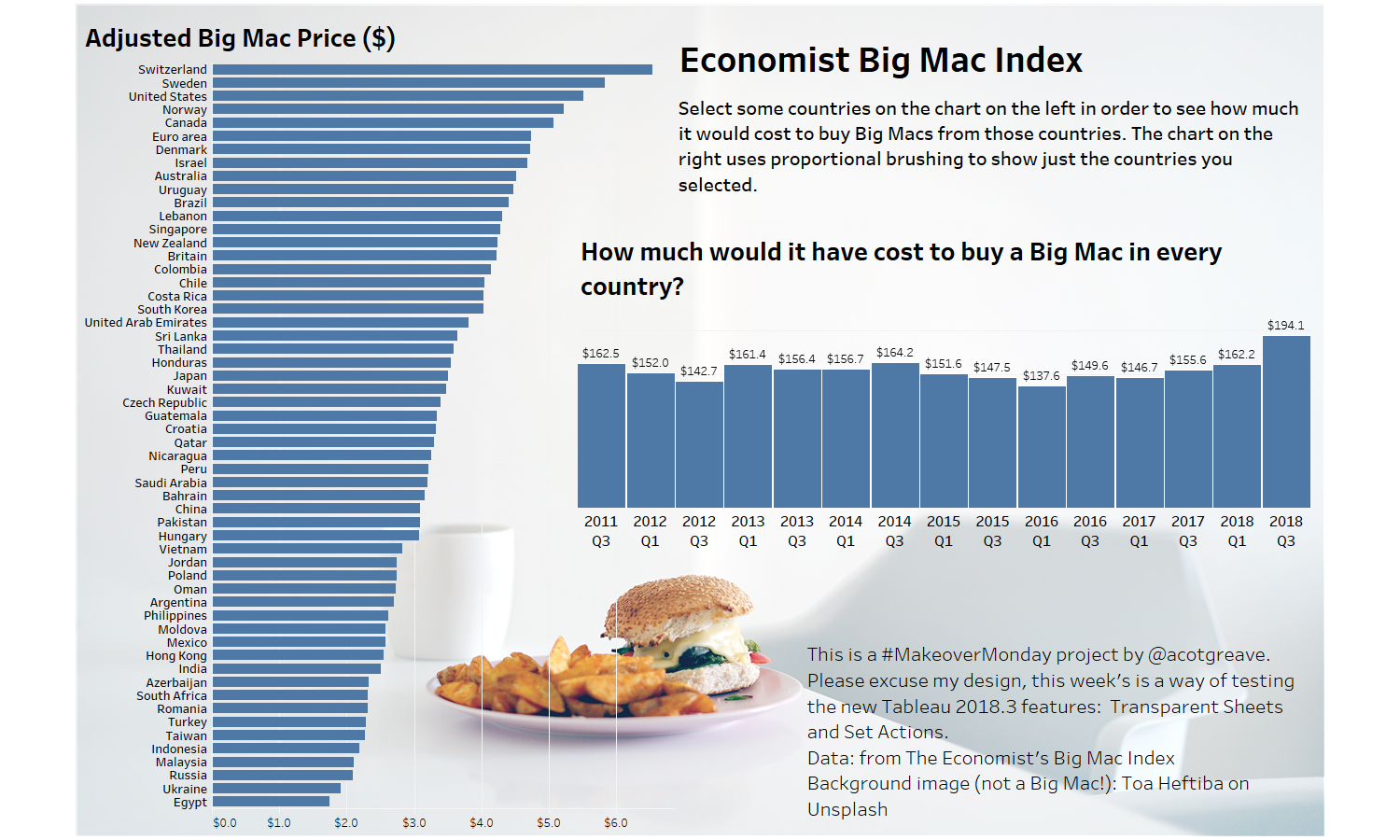
How to do Proportional Highlighting with Set Actions using Tableau 2018.3 (Makeover Monday, July 30 2018) Post date July 30, 2018 Comments 1


Recent Comments