DataPlusMusic: what’s the impact of all these biopics and musicals? Post date July 16, 2019 Comments 0
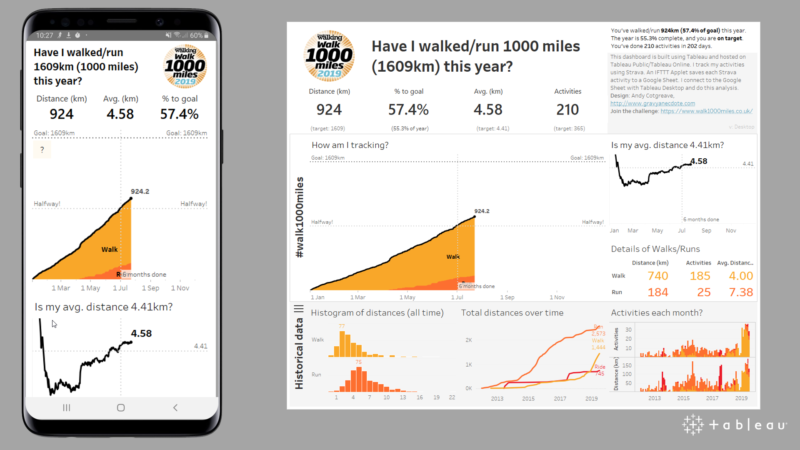
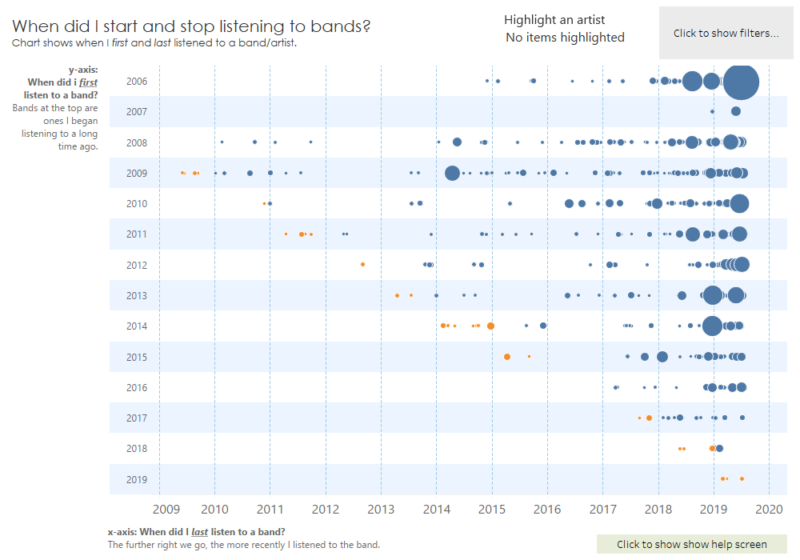
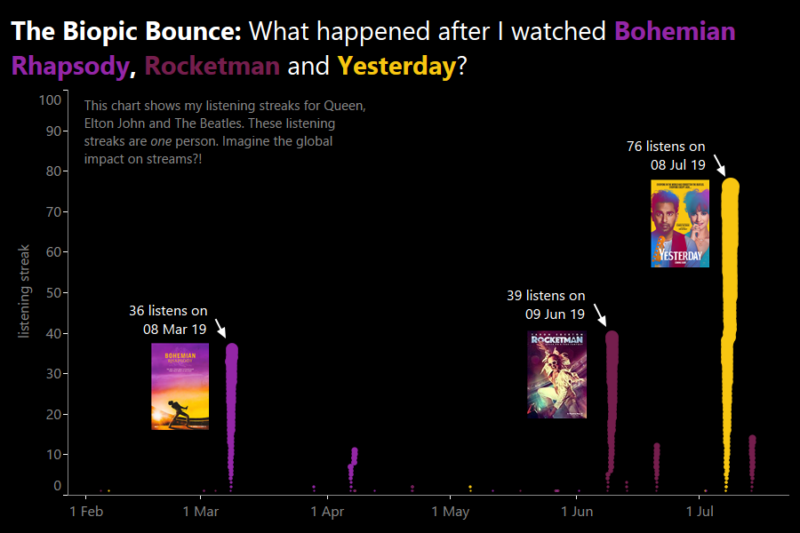
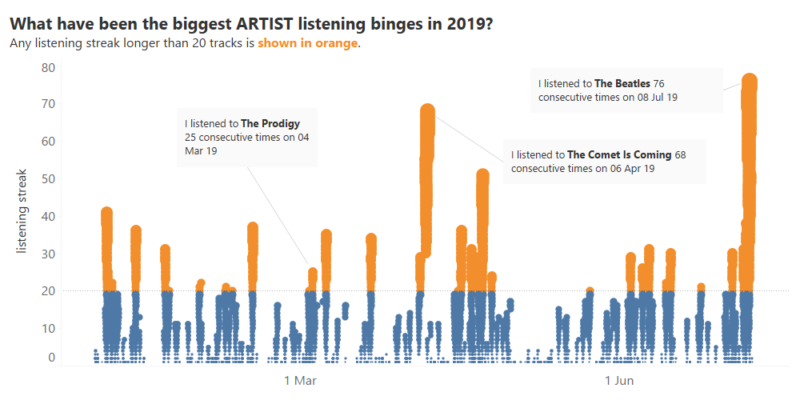
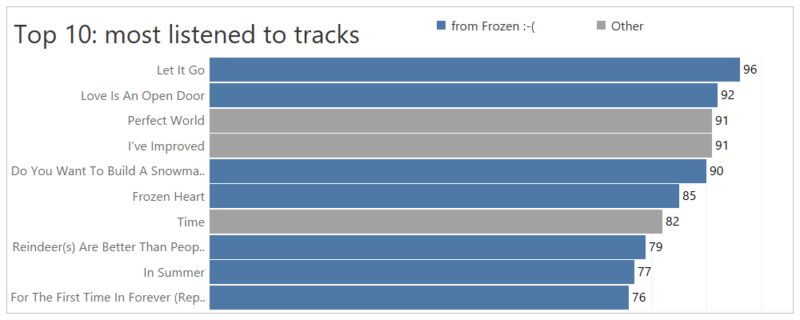
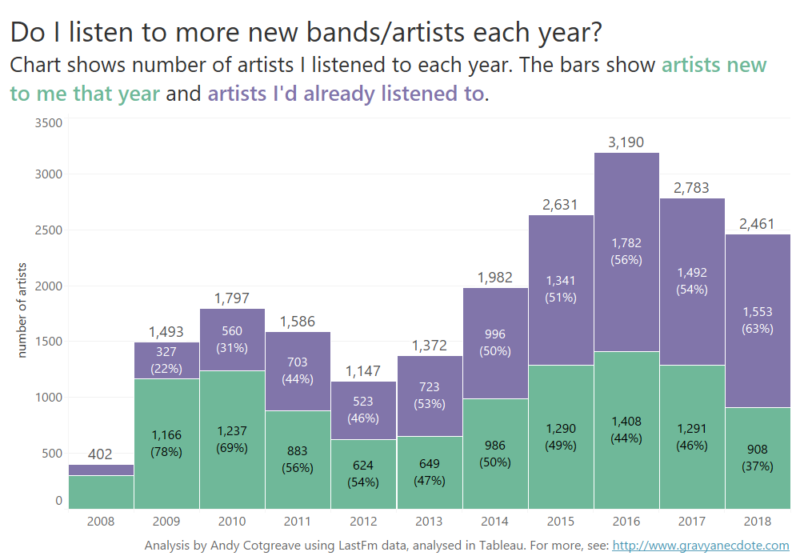
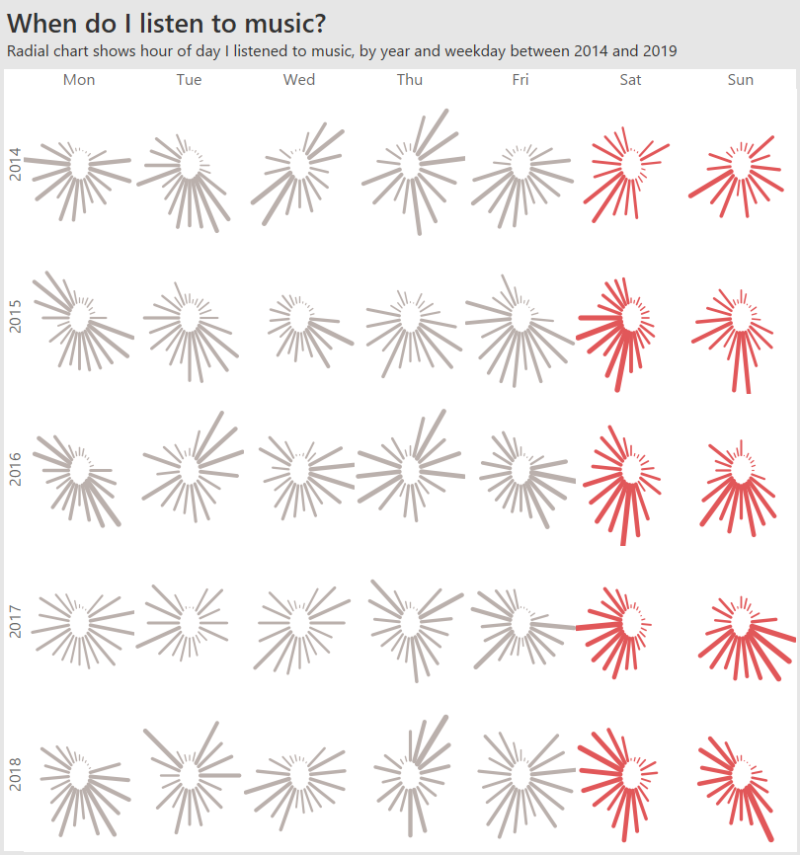
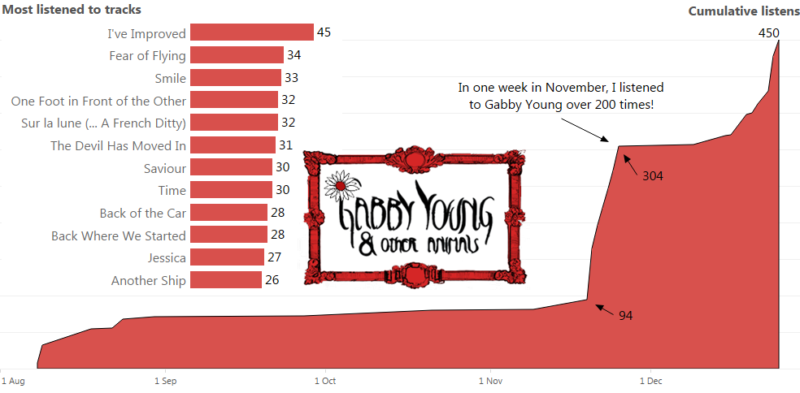
Recent Comments